单词-文档矩阵是表达二者之间所具有的一种包含关系的概念模型。
索引基础
实验数据表明,倒排索引是单词到文档映射关系的最佳实现方式。
倒排索引基本概念
文档(Document):代表以文本形式存在的存储对象
文档集合(Document Collection):若干文档构成的集合
文档编号(Document ID):每个文档的内部编号,简称DocID
倒排索引(Inverted Index):实现单词-文档矩阵的一种具体存储形式。通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由单词词典和倒排文件组成
单词词典(Lexicon):搜索引擎通常的索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息及指向倒排列表的指针
倒排列表(PostingList):倒排列表记载了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)
倒排文件(Inverted File):所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件即被称为倒排文件,倒排文件是存储倒排索引的物理文件。
单词词典
单词词典是倒排索引中非常重要的组成部分,它用来维护文档集合中出现过的所有单词的相关信息,同时用来记载某个单词对应的倒排列表在倒排文件中的位置信息。在支持搜索时,根据用户的查询词,去单词词典里查询,就能够获得相应的倒排列表,并以此作为后续排序的基础。
哈希加链表
这种词典结构主要由两个部分构成,主体部分是哈希表,每个哈希表项保存一个指针,指针指向冲突链表,在冲突链表里,相同哈希值的单词形成链表结构。
树形结构
B树/B+树
倒排列表
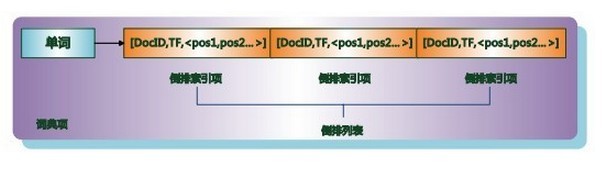
倒排列表用来记录有哪些文档包含了某个单词。 一般在文档集合里会有很多文档包含某个单词,每个文档会记录文档编号(DocID),单词在这个文档中出现的次数(TF)及单词在文档中哪些位置出现过等信息,这样与一个文档相关的信息被称做倒排索引项(Posting),包含这个单词的一系列倒排索引项形成了列表结构,这就是某个单词对应的倒排列表。
在实际的搜索引擎系统中,并不存储倒排索引项中的实际文档编号,而是代之以文档编号差值(DGap)。这是为了更好地对数据进行压缩,通过差值计算,可以将较大的原始文档编号转换为小数值。
建立索引
排序法
-
中间结果内存排序
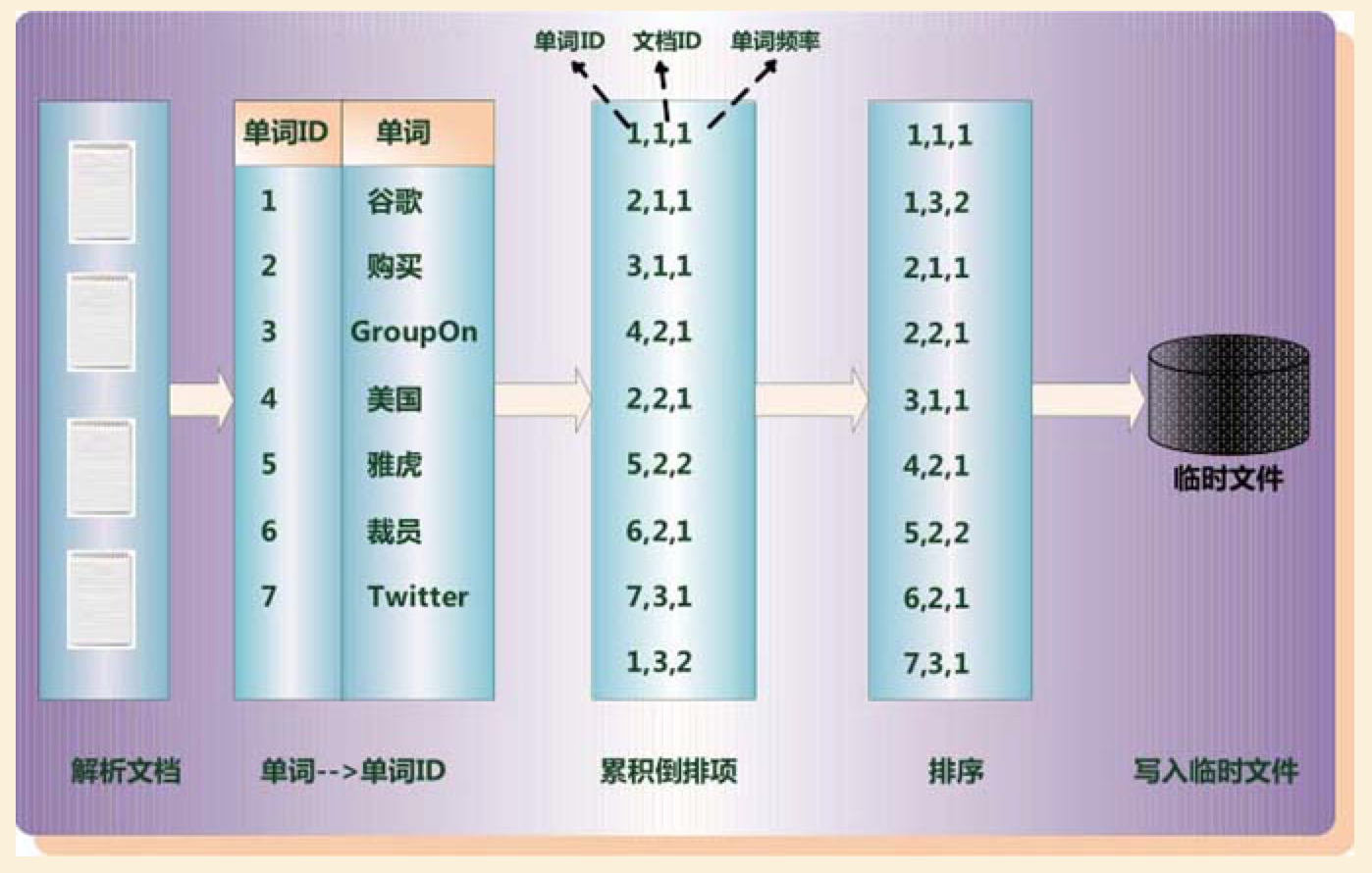
1.1. 读入文档,赋予文档编号
1.2. 解析文档,赋予单词以唯一的单词ID并插入词典
1.2. 构建(单词ID、文档ID、单词频率)三元组
1.3. 当分配的内存定额被占满时,对三元组中间结果排序并写入磁盘。排序主键为单词ID,次键为文档ID -
合并中间结果
2.1. 为每个中间结果文件在内存中开辟一个数据缓冲区,用来存放文件的部分数据
2.2. 将不同缓冲区中包含的同一单词ID的三元组合并。如果某个单词ID的三元组全部合并完成,写入最终索引,同时将各个缓冲区中对应这个单词ID的三元组清空
归并法
归并法相比排序法是在内存中建立一个完整的内存索引结构,相当于对目前处理的文档子集单独在内存中建立起一整套倒排索引。
动态索引(实时)
当系统发现有新文档进入时,立即将其加入临时索引中。有文档被删除时,则将其加入删除文档队列。文档被更改时,则将原先文档放入删除队列,解析更改后的文档内容,并将其加入临时索引中。通过这种方式可以满足实时性的要求。
索引更新策略
完全重建策略
- 当新增文档达到一定数量后,将新增文档和老文档合并
- 重新建立索引
- 新索引建立完成后,替换老索引
重建索引耗时较长,索引重建过程中,内存中仍然需要维护老索引,响应这段时间的用户请求。
目前主流商业搜索引擎一般是采用此方法。
查询处理
一次一文档
先纵向后横向
以倒排列表中包含的文档为单位,每次将其中某个文档与查询的最终相似性得分计算完毕,然后开始计算另一个文档的最终得分,直到所有文档的得分都计算完毕
一次一单词
先横向后纵向
- 将某个单词对应的倒排列表中的每个文档ID都计算一个部分相似性得分
- 计算下一个单词倒排列表中的每个文档ID。如果发现某个文档ID已经有了得分,则在原先得分基础上进行累加
分布式索引
按文档划分
按文档对索引划分,就是将整个文档集合切割成若干子集合,每台机器负责对某个文档子集合建立索引,并响应查询请求。
按单词划分的不足
- 可扩展性。搜索引擎处理的文档集合往往是在不断变动的,当新增文档时,需要更新的服务器更多
- 负载均衡。单词的常见度不同,常用词倒排列表非常庞大
- 容错性。按文档划分,如果某台服务器故障,只会影响到部分文档子集合。而按单词划分,可能某些查询无结果
- 对查询处理方式的支持。按单词划分只能支持一次一单词