Memcached线程模型
线程分析
memcached通过epoll(使用libevent)实现异步的服务器,但仍然使用多线程,主要有两种线程,分别是一个“主线程”和多个“worker线程”。
主线程负责监听网络连接,并且accept连接。当监听到连接时,accept后,连接成功,把相应的client fd丢给其中一个worker线程。 worker线程接收主线程丢过来的client fd,加入到自己的epoll监听队列,负责处理该连接的读写事件。 所以说,主线程和worker线程都各自有自己的监听队列,主线程监听的仅是listen fd,而worker线程监听的则是主线程accept成功后丢过来的client fd。
Libevent
Memcached使用Libevent实现事件监听。Libevent的使用主要有以下几个函数
-
event_base = event_init(); 初始化事件基地。
-
event_set(event, fd, event_flags, event_handler, args);创建事件event,fd为要监听的fd,event_flags为监听的事件类型,event_handler为事件发生后的处理函数,args为调用处理函数时传递的参数。
-
event_base_set(event_base, event); 为创建的事件event指定事件基地。
-
event_add(event, timeval); 把事件加入到事件基地进行监听。
-
event_base_loop(event_base, flag); 进入事件循环,即epoll_wait。
Memcached主线程和worker线程各有自己的监听队列,故有主线程和每个worker线程都有一个独立的event_base,事件基地。
线程模型
-
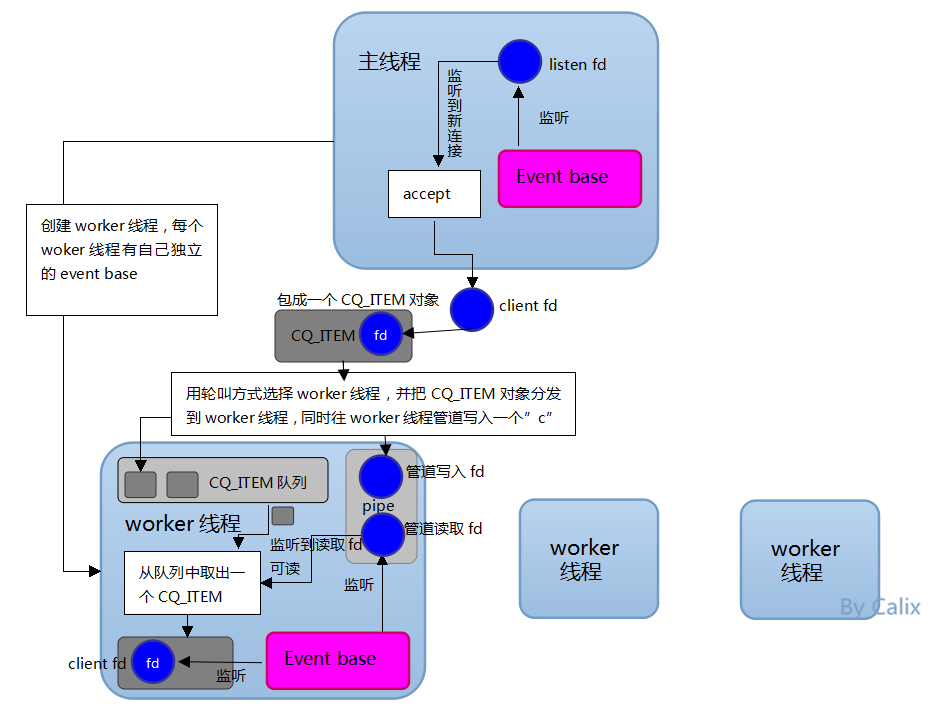
主线程首先为自己分配一个event_base,用于监听连接,即listen fd。
-
主线程创建n个worker线程,同时每个worker线程也分配了独立的event_base。
-
每个worker线程通过管道方式与其它线程(主要是主线程)进行通信,调用pipe函数,产生两个fd,一个是管道写入fd,一个是管道读取fd。worker线程把管道读取fd加到自己的event_base,监听管道读取fd的可读事件,即当主线程往某个线程的管道写入fd写数据时,触发事件。
-
主线程监听到有一个连接到达时,accept连接,产生一个client fd,然后选择一个worker线程,把这个client fd包装成一个CQ_ITEM对象(该结构体下面再详细讲,这个对象实质是起主线程与worker线程之间通信媒介的作用,主线程把client fd丢给worker线程往往不止“client fd”这一个参数,还有别的参数,所以这个CQ_ITEM相当于一个“参数对象”,把参数都包装在里面),然后压到worker线程的CQ_ITEM队列里面去(每个worker线程有一个CQ_ITEM队列), 同时主线程往选中的worker线程的管道写入fd中写入一个字符“c”(触发worker线程)。
-
主线程往选中的worker线程的管道写入fd中写入一个字符“c”,则worker线程监听到自己的管道读取fd可读,触发事件处理,而此是的事件处理是:从自己的CQ_ITEM队列中取出CQ_ITEM对象(相当于收信,看看主线程给了自己什么东西),从4)可知,CQ_ITEM对象中包含client fd,worker线程把此client fd加入到自己的event_base,从此负责该连接的读写工作。
Memcached请求处理
在Memcached线程模型中说到,主线程和worker线程都调用同一个函数conn_new来进行事件监听,并返回conn结构对象。最终有事件到达时,调用同一个函数event_handler最终执行drive_machine。
conn结构体
conn在Memcached里面是这样一个角色,它代表一个“连接”,但这个连接不一定是已经连接上的,也可以是监听中的连接。例如主线程在监听listen fd的时候,也通过conn_new创建了一个conn实例对象,而这个conn对象的conn_states值为conn_listening,代表“监听中的连接”。而worker线程监听的client fd是已经连接上了,也为这个连接创建一个“conn”对象,而连接状态conn_states则不是conn_listening,最开始的时候为conn_cmd_new,这个连接处于“新命令”状态。
每一个“连接”都有当前的状态,监听中,还是等待新命令中,还是后面会看到的“写数据”中,“关闭中”等等。
状态机drive_machine
状态机drive_machine函数是worker线程网络请求进行业务逻辑处理的核心,压缩来说就是:“根据状态不同去做不同的事情”。
一个while循环里面有一个巨大的switch case,根据连接对象 conn当前的连接状态conn_state,进入不同的case,而每个case可能会改变conn的连接状态,也就是说在这个while+switch中,conn会不断的发生状态转移,最后被分发到合适的case上作处理。可以理解为,这里是一个有向图,每个case是一个顶点,有些case通过改变conn对象的连接状态让程序在下一次循环中进入另一个case,几次循环后程序最终进入到“无出度的顶点”然后结束状态机,这里的无出度的顶点就是带设置stop=true的case分支。
Memcached内存管理
Memcached的内存管理机制有3个重要的概念:slabclass,slab和item。
如果把slab看作是一张A4纸。不同的纸格子大小不同,有40个格子的,有100个格子的,每一个格子是一个chunk / item。
而slabclass就可以看成是一个作业本,有多个格子数相同的slab,是slab的数组。
三者的对应关系如下:
item –> slab –> slabclass
格子 –> A4纸 –> 本子
item的growth factor为1.25。
内存分配模型
-
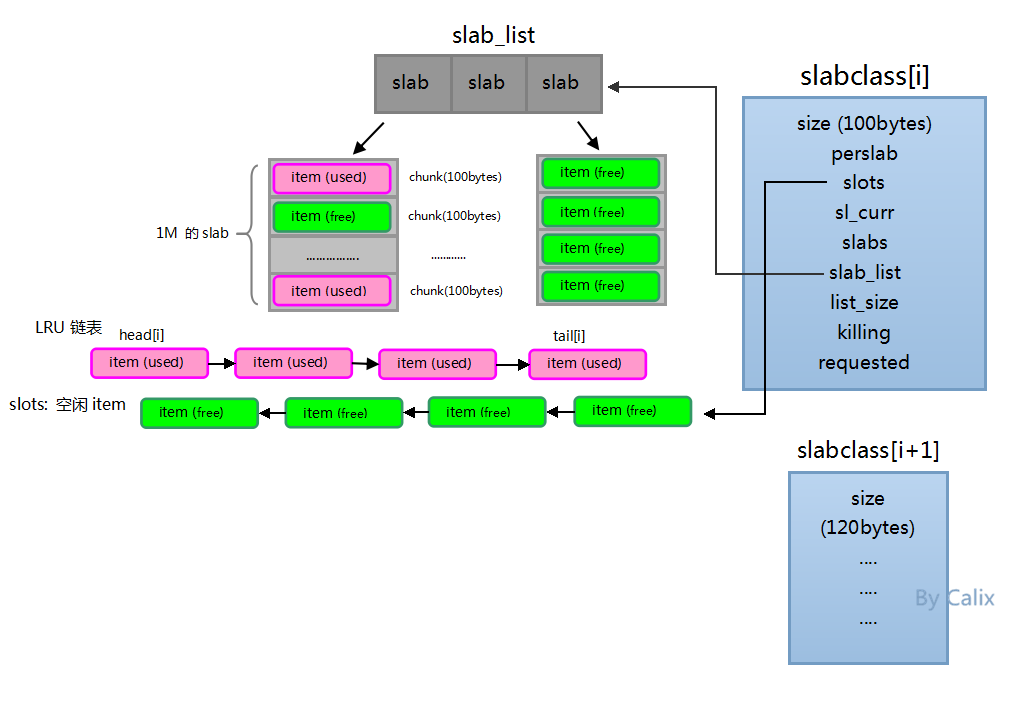
初始化slabclass数组,每个元素slabclass[i]都是不同size的slabclass。
-
每开辟一个新的slab,都会根据所在的slabclass的size来分割chunk,分割完chunk之后,把chunk空间初始化成一个个free item,并插入到slot链表中。
-
我们每使用一个free item都会从slot链表中删除掉并插入到LRU链表相应的位置。
-
每当一个used item被访问的时候都会更新它在LRU链表中的位置,以保证LRU链表从尾到头淘汰的权重是由高到低的。
-
会有另一个叫“item爬虫”的线程(以后会讲到)慢慢地从LRU链表中去爬,把过期的item淘汰掉然后重新插入到slot链表中(但这种方式并不实时,并不会一过期就回收)。
-
当我们要进行内存分配时,例如一个SET命令,它的一般步骤是:
a. 计算出要保存的数据的大小,然后选择相应的slabclass进入下面处理:
b. 首先,从相应的slabclass LRU链表的尾部开始,尝试找几次(默认是5次),看看有没有过期的item(虽然有item爬虫线程在帮忙查找,但这里分配的时候,程序还是会尝试一下自己找,自己临时充当牛爬虫的角色),如果有就利用这个过期的item空间。
c. 如果没找到过期的,则尝试去slot链表中拿空闲的free item。
d. 如果slot链表中没有空闲的free item了,尝试申请内存,开辟一块新的slab,开辟成功后,slot链表就又有可用的free item了。
e. 如果开不了新的slab那说明内存都已经满了,用完了,只能淘汰,所以用LRU链表尾部找出一个item淘汰之,并作为free item返回。
Memcached内存页重分配
考虑这样的一个情景:在一开始,由于业务原因向memcached存储大量长度为1KB的数据,也就是说memcached服务器进程里面有很多大小为1KB的item。现在由于业务调整需要存储大量10KB的数据,并且很少使用1KB的那些数据了。由于数据越来越多,内存开始吃紧。大小为10KB的那些item频繁访问,并且由于内存不够需要使用LRU淘汰一些10KB的item。
对于hash表而言,大量的僵尸item会增加hash冲突率,且在迁移hash表时也浪费时间。使用LRU爬虫 + LUR_crawler命令可以干掉僵尸item,但是会把内存归还到当前slabclass。
此时,我们就需要一个把1KB的item重分配给10KBitem用的功能。Memcached提供的slab automove和rebalance两个东西就是完成这个功能的。在默认情况下,Memcached不启动这个功能,所以要想使用这个功能必须在启动memcached的时候加上参数-o slab_reassign。之后就可以在客户端发送命令slabsreassign <source class> <dest class>,手动将source class的内存页分给dest class。而命令slabs automove则是让memcached自动检测是否需要进行内存页重分配,如果需要的话就自动去操作,这样一切都不需要人工的干预。
当settings.slab_reassign为true,也就是启动rebalance功能的时候,slabclass数组中所有slabclass_t的内存页都是一样大的,等于settings.item_size_max(默认为1MB)。这样做的好处就是在需要将一个内存页从某一个slabclass_t强抢给另外一个slabclass_t时,比较好处理。
自动检测功能由全局变量settings.slab_automove控制(默认值为0,0就是不开启)。如果要开启可以在启动Memcached的时候加入slab_automove选项,并将其参数数设置为1。比如命令$memcached -o slab_reassign,slab_automove=1就开启了自动检测功能。当然也是可以在启动memcached后通过客户端命令启动automove功能,使用命令slabsautomove <0|1>。其中0表示关闭automove,1表示开启automove。
Automove线程
automove线程要进行自动检测,检测就需要一些实时数据进行分析。然后得出结论:哪个slabclass_t需要更多的内存,哪个又不需要。automove线程通过全局变量itemstats收集item的各种数据。itemstats变量是一个数组,它是和slabclass数组一一对应的。itemstats数组的元素负责收集slabclass数组中对应元素的信息。itemstats_t结构体虽然提供了很多成员,可以收集很多信息,但automove线程只用到一个成员evicted。automove线程需要知道每一个尺寸的item的被踢情况,然后判断哪一类item资源紧缺,哪一类item资源又过剩。evicted记录该slabclass因为LRU被踢的item数。
itemstats[id].evicted只在do_item_alloc()函数中出现,如果某个item因为LRU被踢了,该变量增1.
Memcached过期处理
一个item在两种情况下会过期失效:
- item的exptime时间戳到了。
- 用户使用flush_all命令将全部item变成过期失效。
超时失效
Memcached对于超时失效的处理是懒惰处理:不主动检测一个item是否过期失效。当worker线程访问这个item时,才检测这个item的exptime时间戳是否到了。
Flush_all
用户使用flush_all命令会将所有item都变成过期失效。客户端会不断地向Memcached插入item,那么这个界限是什么呢。
当worker线程接收到flush_all命令后,会用全局变量settings的oldest_live成员存储接收到这个命令那一刻的时间(准确地说,是worker线程解析得知这是一个flush_all命令那一刻再减一),代码为settings.oldest_live =current_time - 1;然后调用item_flush_expired函数锁上cache_lock,然后调用do_item_flush_expired函数完成工作。
worker线程在do_item_flush_expired中会删除item->time > settings.oldest_live的item。而剩余更早的更多的item采用懒惰处理。
Memcached的LRU爬虫
Memcached默认是懒惰删除过期的item的。有没有强制清除这些过期item,不再占用hash表和LRU队列并把空间归还slabs的方法呢?答案就是LRU爬虫。
要使用LRU爬虫需要在客户端使用lru_crawler命令-o lru_crawler来启动这个线程。也可以通过客户端命令启动。另外,还需要发送命令,指明对哪个LRU队列进行清除处理。
LRU爬虫流程
-
lru_crawler <enable|disable>启动一个LRU爬虫流程。 -
lru_crawler tocrawl <32u>指定每一个LRU队列最多检查num-1个item。
[3]. lru_crawler sleep <microseconds> 选设。LRU爬虫在清除item时会占用锁,妨碍worker线程的正常业务,所以LRU爬虫时要不时地休眠一下,别老耽误别人的大好青春。
lru_crawler crawl <classid, classid, classid|all>指定要处理的LRU队列。
清除失效item
怎么对一条LRU队列进行清理?最直观的做法是先加锁(锁上cache_lock),然后遍历一整条LRU队列。直接判断LRU队列里面的每一个item即可。明显这种方法有问题。如果memcached有大量的item,那么遍历一个LRU队列耗时将太久。这样会妨碍worker线程的正常业务。当然我们可以考虑使用分而治之的方法,每次只处理几个item,多次进行,最终达到处理整个LRU队列的目标。但LRU队列是一个链表,不支持随机访问。处理队列中间的某个item,需要从链表头或者尾依次访问,时间复杂度还是O(n)。
Memcached采用了一个伪item的方法来使LRU队列支持随机访问。它在LRU队列尾部插入一个伪item,然后驱动这个伪item向队列头部前进,每次前进一位。
static crawler crawlers[largest_ID]
这个伪item(crawler)是全局变量,每个slabclass有一个crawler。LRU爬虫线程无须从LRU队列头部或者尾部遍历就可以直接访问这个伪item。通过这个伪item的next和prev指针,就可以访问真正的item。于是,LRU爬虫线程无需遍历就可以直接访问LRU队列中间的某一个item。
Memcached系统架构图
下图是Memcached系统架构图,如果有错误或者不准确的地方,敬请纠正。
-
四个大框架是不同的文件
-
每个组合框是一个函数
-
每种颜色是一个功能系列

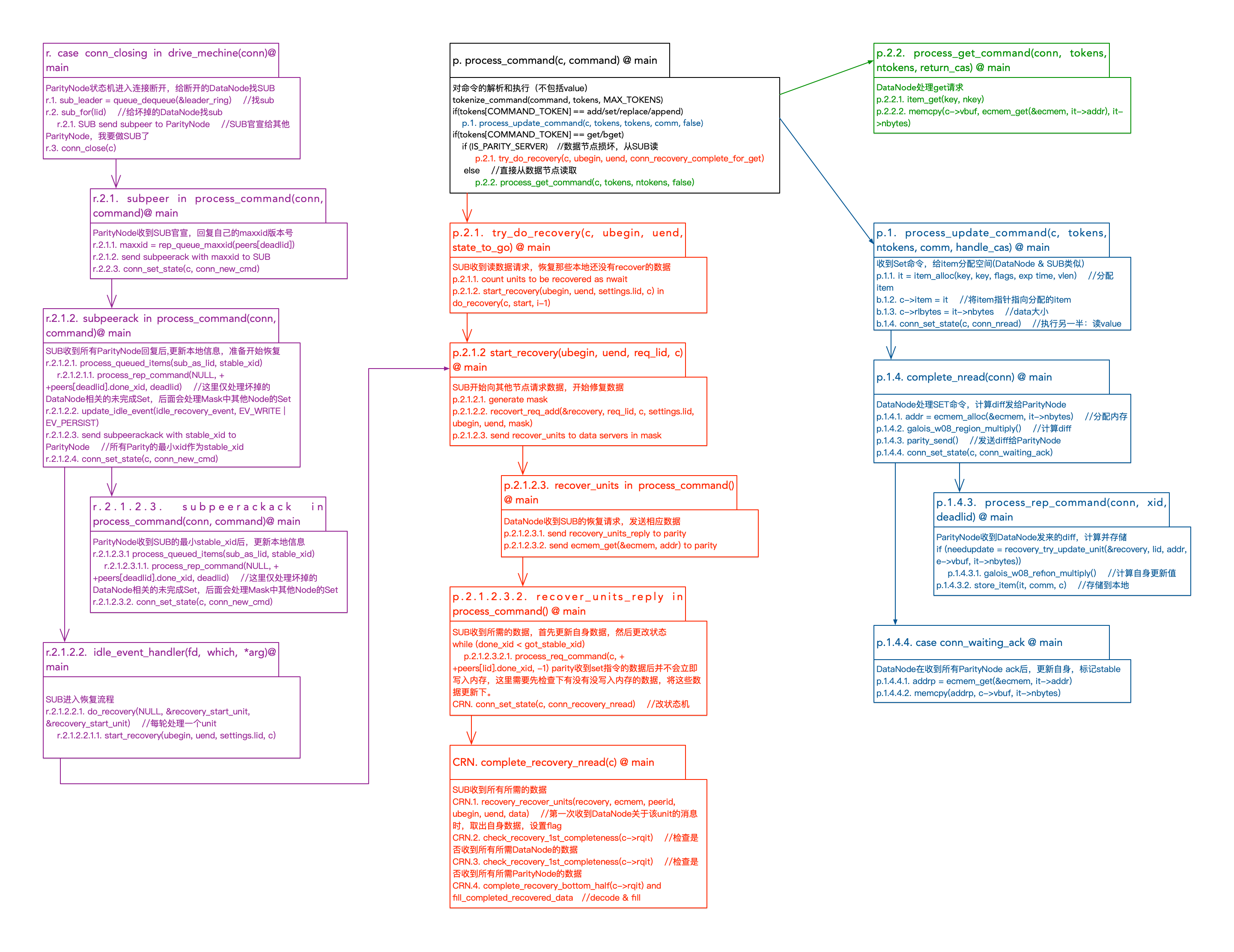
Cocytus读写流程
下图是Cocytus(Memcached + RSCodes)系统读写流程。